こんにちは、hachi8833です。先週終点で車両の座席に置き忘れたiPhone 7が粉々になって戻ってきて風景がぐらりとかしいだ気がしましたが、補償が効いて本体交換できてケロッと立ち直りました。春ですねぇ。
![]()
春たけなわのウォッチ、いってみましょう。
Rails: 今週の改修
5.2はまだ出ていませんが、ドキュメント更新が増えていて、収束に近づいていることを感じさせます。今週も5.2-stableと6.0向けmasterの両方から見繕いました。いずれも変更の可能性がありますので。
Rails 5.1->5.2アップグレードドキュメント
まずは5.2-stableから。CSPとドキュメント周りの改修が目立ちます。
一応現時点のアップグレードドキュメントです↓。今のところ作業量は少なくて済みそう。
Rails 5.1からRails 5.2へのアップグレード
* Bootsnap
#29313でRails 5.2からBootsnap gemが含まれるようになりました。app:updateタスクはboot.rbで設定されます。使いたい場合はGemfileにこのgemを追加し、使わない場合はBootsnapを使わないようにboot.rbを変更してください。
- cookie値に署名済みまたは暗号化cookieの有効期限が設定されるようになった
セキュリティ向上のため、署名済みまたは暗号化cookieの値に有効期限の情報が埋め込まれるようになりました。これによって、5.2より前のRailsとcookieバージョンの互換性が失われます。5.1以前のcookieが必要な場合や、5.2デプロイを検証中でロールバックの道を残しておきたい場合は、Rails.application.config.action_dispatch.use_authenticated_cookie_encryptionをfalseに設定してください。
同コミットより大意
つっつきボイス: 「bootsnapはShopifyのgemがRailsで標準採用になったやつですね」「Shopfyはカナダのオタワですって」「運用中のサーバーでcookieの互換性が失われると、挙動としてはたとえば強制ログアウトが発生したりとか」「ソシャゲみたいにユーザーがめちゃ多いサービスでcookieが一斉に切れるとヤバイ: ユーザーが再ログインしようとして一気に押しかけて、ログインサーバーに負荷が集中してお亡くなりになったりとか」
その後ロードバランサーなどの話題になりました。
Railsエンジンを場所を変えてマウントできるようになった
# actionpack/lib/action_dispatch/routing/mapper.rb#L652
def define_generate_prefix(app, name)
_route = @set.named_routes.get name
_routes = @set
- app.routes.define_mounted_helper(name)
+
+ script_namer = ->(options) do
+ prefix_options = options.slice(*_route.segment_keys)
+ prefix_options[:relative_url_root] = "".freeze
+ # We must actually delete prefix segment keys to avoid passing them to next url_for.
+ _route.segment_keys.each { |k| options.delete(k) }
+ _routes.url_helpers.send("#{name}_path", prefix_options)
+ end
+
+ app.routes.define_mounted_helper(name, script_namer)
+
app.routes.extend Module.new {
def optimize_routes_generation?; false; end
+
define_method :find_script_name do |options|
if options.key? :script_name
super(options)
else
- prefix_options = options.slice(*_route.segment_keys)
- prefix_options[:relative_url_root] = "".freeze
- # We must actually delete prefix segment keys to avoid passing them to next url_for.
- _route.segment_keys.each { |k| options.delete(k) }
- _routes.url_helpers.send("#{name}_path", prefix_options)
+ script_namer.call(options)
end
end
}
これは実は昨年のコミットですが、#793c11dのコミットメッセージで目に止まったので。
つっつきボイス: 「同じマウンタブルエンジンを別名でマウントできるようになったと」「マウンタブルエンジン使うのって、Sidekiqの管理画面をマウントするときぐらいだけどなっ」「あとletter_opener導入するとエンジン入ってブラウザで見られますね」
CSPがWelcomeページやmailerプレビュー表示を邪魔しないよう修正
# railties/lib/rails/application_controller.rb#L7
+ before_action :disable_content_security_policy_nonce!
+
+ content_security_policy do |policy|
+ if policy
+ policy.script_src :unsafe_inline
+ policy.style_src :unsafe_inline
+ end
+ end
...
+ def disable_content_security_policy_nonce!
+ request.content_security_policy_nonce_generator = nil
+ end
つっつきボイス: 「こうやって追いかけているとわかりますが、最近のRailsではこういうCSP周りがちょくちょくアップデートされてますね」
CSPをコントローラからオフにできる機能を追加
# actionpack/lib/action_controller/metal/content_security_policy.rb#L16
module ClassMethods
- def content_security_policy(**options, &block)
+ def content_security_policy(enabled = true, **options, &block)
before_action(options) do
if block_given?
policy = request.content_security_policy.clone
yield policy
request.content_security_policy = policy
end
+
+ unless enabled
+ request.content_security_policy = nil
+ end
end
end
つっつきボイス: 「オンにできるならオフにできないとね」「たしかに」
CSPポリシーインスタンスを常にyieldするように変更
# actionpack/lib/action_controller/metal/content_security_policy.rb#L17
def content_security_policy(enabled = true, **options, &block)
before_action(options) do
if block_given?
- policy = request.content_security_policy.clone
+ policy = current_content_security_policy
yield policy
request.content_security_policy = policy
end
...
+
+ def current_content_security_policy
+ request.content_security_policy.try(:clone) || ActionDispatch::ContentSecurityPolicy.new
+ end
つっつきボイス: 「cloneやめて常に同一のCSP設定を参照できるようにしたと: でないと挙動を追ったり変更したりできないですからね」
i18nドキュメント更新
- 存在しなくなった
Globalize::Backend::Staticへの参照を削除
- Google Groupsへの参照を削除
- Globalize3への参照を削除(紛らわしいので)
- 保存したコンテンツの翻訳方法についてのセクションを追加
本ガイドに記述されているI18n APIは、主にUI文字列の翻訳への利用を意図しています。モデルのコンテンツの翻訳手法をお探しの場合は、UI文字列とは別のソリューションが必要です。
モデルコンテンツの翻訳で役立ついろいろなgemがあります。
- Globalize: 翻訳用の別テーブルに訳文を保存できます。1つのテーブルが1つの翻訳済みモデルになります。
- Mobility: 訳文用テーブルやJSON columns(PostgreSQL)などさまざまな形式で訳文を保存できます。
- Traco: Rails 3や4向けの翻訳可能なカラムを使えるようにします。カラムは元のテーブル自身に保存します。
ガイド更新箇所より大意(強調はTechRacho編集部)
i18nのサードパーティgemがいくつか公式ガイドに載ったのが目に止まりました。
つっつきボイス: 「お、i18n gemを紹介してくれるようになるのか!」「公式が推してくれるのはうれしいっすね」「今のところGlobalizeがメジャーらしいです」「↑上にも書いてますがUI翻訳のyamlはRailsでサポートするけどコンテンツの方はRailsがサポートすることは今後もないだろうから、こういう形にしたのかも」
「モデルのi18nは自力で実装するとつらいよw: 昔やったけど当時はこういうgemなかったんで」「あ、例のMangaRebornですね」「たとえばサイトにデフォルト言語を設定したりとか、フォールバックする言語を指定したりとか必要になってくるので」「台湾語がなければ中国語、みたいな」
「Mobilityは例のshioyamaさんです↓: 名字のSalzbergをそのままもじってますね」
RubyのModule Builderパターン #1 モジュールはどのように使われてきたか(翻訳)
「こういうi18n gemは、コードを追うまではしないとしても、どういうインターフェイスを用意しているかという部分に注目して比較してみると結構勉強になりますよ: みんなそれぞれ個性があって」
ルーティングガイド更新
Railsのルーティング設定
アプリやエンジンのルーティングはconfig/routes.rbに保存されます。以下は典型的な外観です。
Rails.application.routes.draw do
resources :brands, only: [:index, :show]
resources :products, only: [:index, :show]
end
resource :basket, only: [:show, :update, :destroy]
resolve("Basket") { route_for(:basket) }
end
これは普通のRubyソースファイルなので、Rubyのあらゆる機能を用いてルーティングを定義できますが、変数名がルーターのDSLと衝突しないようにご注意ください。
メモ: ルーティング定義を囲むRails.application.routes.draw do ... endブロックは、ルーターのDSLがスコープを確立するために必要なので絶対に削除しないでください。
ガイド更新箇所より大意(強調はTechRacho編集部)
つっつきボイス: 「Railsのルーティングの包括的というか完全なドキュメントが欲しいっすねマジで: 機能はやたらめったらあるけど、知らないと使いようのない機能の多さではRails内ではトップかも」
「今頃変数名にはご注意…だと?」「asとか使うとヘルパーが自動生成されたりとかゴロゴロありますからねー」「まRailsに慣れてくると『この語はキケン』みたいなのをだんだん身体で思い知るけど」「(´・ω・`)」
Railsのルーティングを極める(前編)
「そうそう、sheepみたいに単数形複数形が同じ語を使うと、生成されるヘルパー名が通常と違ってくることあります」「え~~!」
resources :penguins
# 通常は以下が生成される
penguin_path(@penguin)
penguins_path
resources :sheep
#
sheep_path(@sheep)
sheep_index_path # 区別のため「_index」が付く
「ActiveSupportにそういう活用形をチェックするメソッドがある↓」「それは知ってたけど…くぅ」「活用形といえばdataは複数形で、単数形はdatum: みんなもう知ってるよね!」
[Rails5] Active Support::Inflectorの便利な活用形メソッド群
ラテン語由来の英単語はたいてい不規則活用になりますね。symposionとsymposiumとか。ちょっと話はそれますが、indexの複数形はindicesが正式とされていますが、近年急速にすたれつつある印象です。
ActiveSupport::Cache::Entryをメモ化してマーシャリングの負荷を軽減
これは5.2-stableとmasterの両方に入っていました。ここからはmasterです。
# activesupport/lib/active_support/cache.rb#L806
+ def marshaled_value
+ @marshaled_value ||= Marshal.dump(@value)
+ end
メモ化といえば、おなじみ「縦縦イコール」ですね。
つっつきボイス: 「kazzさんが以前『たてたてイコール』って呼んでたのが可愛かったのでw」「本当は何て言うんだっけ?」「『オアイコール』?」
「ちなみに以前も話したことあるけど、Marshal.dumpはRubyのバージョンが変わると互換性が失われることがあるので、データベースにそのまま保存すると後で痛い目に遭うかもよ」「怖!」
起動メッセージの無意味な「Exiting」を除去
# railties/lib/rails/commands/server/server_command.rb#L158
if server.serveable?
print_boot_information(server.server, server.served_url)
- server.start do
- say "Exiting" unless options[:daemon]
- end
+ after_stop_callback = -> { say "Exiting" unless options[:daemon] }
+ server.start(after_stop_callback)
else
say rack_server_suggestion(using)
end
rails routes --expandedの横線をきれいにした
$ rails routes --expanded
--[ Route 1 ]------------------------------------------------------------
-------
(snip)
--[ Route 42 ]-----------------------------------------------------------
--------
(snip)
--[ Route 333 ]----------------------------------------------------------
---------
(snip)
$ rails routes --expanded
--[ Route 1 ]------------------------------------------------------------
(snip)
--[ Route 42 ]-----------------------------------------------------------
(snip)
--[ Route 333 ]----------------------------------------------------------
(snip)
つっつきボイス: 「前は横棒固定か」「IO.console.winsizeって初めて知った: これならターミナルに合わせて調整できるし」「地味だけどありがたい修正!」
+ previous_console_winsize = IO.console.winsize
+ IO.console.winsize = [0, 23]
参考: Rubyリファレンスマニュアル IO.console
rails routes -gで結果が空の場合のメッセージを修正
ActionDispatch::Routingのドキュメント更新
-gの記述を追加rails routesの--expandedオプションの説明を追加
ActionDispatch::Routing::ConsoleFormatter::Baseの導入
Baseを作ってSheetとExpandedで継承し、コード重複を防止
Expandedのコンポーネントで末尾の”\n”を削除Expanded#headerの戻り値を@bufferからnilに変更
-gのときのno_routesメッセージがよくなかったので修正
-cの場合のメッセージは「Display No routes were found for this controller」-gの場合のメッセージは「No routes were found for this grep pattern」
PRメッセージより大意
# actionpack/lib/action_dispatch/routing.rb#L85
def normalize_filter(filter)
- if filter.is_a?(Hash) && filter[:controller]
+ if filter[:controller]
{ controller: /#{filter[:controller].downcase.sub(/_?controller\z/, '').sub('::', '/')}/ }
- elsif filter
- { controller: /#{filter}/, action: /#{filter}/, verb: /#{filter}/, name: /#{filter}/, path: /#{filter}/ }
+ elsif filter[:grep_pattern]
+ {
+ controller: /#{filter[:grep_pattern]}/,
+ action: /#{filter[:grep_pattern]}/,
+ verb: /#{filter[:grep_pattern]}/,
+ name: /#{filter[:grep_pattern]}/,
+ path: /#{filter[:grep_pattern]}/
+ }
end
end
つっつきボイス: 「最近自分はブラウザで/rails/info/routesで見ちゃうこと多いかなー」「このパスが割りと覚えにくいという」「/aとか打ってルーティングエラー出す方が早いっすね」「たしかに」
Rails
Railsビューをin_groups_ofでリファクタリング(RubyFlowより)
// 同記事より
%table.sponsors{width: "100%;"}
- sponsors_by_level.levels.each do |level|
- level.sponsors.in_groups_of(level.sponsors_per_line, false) do |group|
%tr
- group.each do |sponsor|
%td{colspan: 12 / group.size, style: "text-align: center !important;"}
= link_to sponsor.path do
= image_tag(sponsor.logo_url, alt: sponsor.name, title: sponsor.name, style: "display: inline; float: none;")
%tr
%td{colspan: 12}
%hr
つっつきボイス: 「ほっほー、in_groups_ofとな」「内部でeach_slice使ってるからこれを直接使う方が早かったかも、だそうです」「改修前のhaml、見たくないやつ…」
参考: in_groups_of
参考: Rubyリファレンス・マニュアル each_slice
RailsのシステムテストでJSエラーをキャッチする方法(RubyFlowより)
WARN: javascript warning
http://127.0.0.1:60979/assets/application.js 9457 Synchronous XMLHttpRequest on the main thread is deprecated because of its detrimental effects to the end user’s experience.
Got 3 failures and 1 other error from failure aggregation block “javascript errrors”:
1) http://127.0.0.1:60481/sso 10:18 Uncaught SyntaxError: Unexpected token ;
同記事より
つっつきボイス: 「テーブル使うのはどうかと思うけどまあそれはおいといて」「どうやらきれいにキャッチする方法がないからコンソールに出力してそっちで見れ、ってことみたい」「たしかに原理的に難しそう」
Railsのメール設定でdeliverやdeliver_nowは使うな(Hacklinesより)
deliver_laterにしとけ、だそうです。
# 同記事より
class User
after_update :send_email
def send_email
ReportMailer.update_mail(id).deliver_later
end
end
つっつきボイス: 「deliver_nowは同期的なのか: じゃあ使いたくないやつですね」「deliver_laterで非同期になると、それはそれでテストで考慮しないといけない点が増えて大変になるけど: キューに入ったりメールサーバーが応答したりしてもそれだけでよしとできないとか」「キューに入ってコケたかどうか、とか」
参考: Rails API deliver_later
RailsでReduxのフォームを使うには(Awesome Rubyより)
![]()
redux-form.comより
# 同記事より
def create
authorize resource_plan, :create?
command = GlobalContainer['plan.services.create_plan_command'] #Plan::CreatePlan.new
respond_to do |format|
format.json {
command.call(resource_plan, params[:plan]) do |m|
m.success do |plan|
flash[:notice] = t('messages.created', resource_name: Plan.model_name.human)
render json: { id: plan.id}, status: :ok, location: settings_plan_path(plan)
end
m.failure do |form|
render json: {
status: :failure,
payload: { errors: form.react_errors_hash }
}, status: 422
end
end
}
end
end
Redux-Formでうまく書けたそうです。Redux-Formは完成途上らしいので、末尾でFinal Formというフレームワーク非依存JSフォームライブラリも紹介しています。
![]()
github.com/final-form/final-formより
つっつきボイス: 「コードの中でRepresenterというのを置いてますね」
HABTMをhas_many throughに置き換える(RubyFlowより)
# 同記事より
class PostTag < ApplicationRecord
belongs_to :post
belongs_to :tag
end
class Post < ApplicationRecord
has_many :post_tags, -> { order(rank: :asc) }
has_many :tags, through: :post_tags
end
class Tag < ApplicationRecord
has_many :post_tags
has_many :posts, through: :post_tags
end
つっつきボイス: 「絵に描いたようなHABTMリファクタリングですが、基本ということで」
参考: 仕事のねた: rails3でHABTMが非推奨になってる
Railsで巨大データをdedupする(Hacklinesより)
# 同記事より
# log.rb
class Log < ActiveRecord::Base
has_many :user_logs
def store(data)
key = Digest::MD5.hexdigest(data)
log = Log.find_by_checksum(key)
if log.nil?
log = Log.new(data: data, checksum: key)
Log.transaction(requires_new: true) do
begin
log.save!
rescue ActiveRecord::RecordNotUnique => e
raise ActiveRecord::Rollback
end
end
end
log
end
end
ActiveRecordリレーションをyield_selfでコンポジション可能にする(Hacklinesより)
# 同記事より
def call
base_relation.
joins(:care_periods).
yield_self(&method(:care_provider_clause)).
yield_self(&method(:hospital_clause)).
yield_self(&method(:discharge_period_clause))
end
private
def care_provider_clause(relation)
if params.care_provider_id.present?
relation.where(care_periods: { care_provider_id: params.care_provider_id })
else
relation
end
end
...
つっつきボイス: 「yield_selfってどっかで見たゾ」「あーこれだ↓」「そうそう、tapしないで書けるというのはちょっといいかも」「tapだとビックリマーク付きのwhere!になりますね: 破壊的にならないからいいだろ?っていう趣旨なのかな」「別に破壊的でもいい気はするけど」「メモリ効率とかの話を別にすれば、イミュータブルな方が望ましくはあるし、where!は基本使いたくはないので気持ちはわかる」
Ruby 2.5の`yield_self`が想像以上に何だかスゴい件について(翻訳)
RailsアプリをHerokuからAWSに移して年8万ドル以上節約した件について(Awesome Rubyより)
![]()
つっつきボイス: 「1000万近くって以前どれだけザルだったのかとw」「ちゃんと読んでないけど、HerokuとAWSの違いというより設定が大きかったんじゃ?」
search_flip: ElasticSearchクエリをチェインするクライアント(RubyFlowより)
★はまだ少ないです。
つっつきボイス: 「類似のgemがあるんではないかと思って」「ははあ、searchkickと違ってハッシュ使わずに書けるぞ↓ドヤアってことかな」
# 同リポジトリより
# elasticsearch-ruby
Comment.search(
query: {
query_string: {
query: "hello world",
default_operator: "AND"
}
}
)
# searchkick
Comment.search("hello world",
where: { available: true },
order: { id: "desc" },
aggs: [:username])
# search_flip
CommentIndex.where(available: true)
.search("hello world")
.sort(id: "desc")
.aggregate(:username)
RabbitMQはSidekiqの単なる置き換え以上のものだ(RubyFlowより)
![]()
つっつきボイス: 「熱烈にRabbitMQ推してますね: 永続性の保証とかで違ってくるみたい」「Sidekiqだって用途に合ってればとってもいいヨって最後に書いてますね」
![]()
rabbitmq.comより
![]()
sidekiq.orgより
Railsデプロイ前にこれだけはチェックしたい5項目(RubyFlowより)
- public/404.htmlとか設定したか
- HTTPSにしたか
- URLでデータベース内容がお漏らししないようにしたか
- 監視設定やったか
- デプロイを自動化したか
# 同記事より
class User < ApplicationRecord
has_secure_token :uuid # DBでUNIQUE indexにしておけばベスト
def to_param
self.uuid
end
end
つっつきボイス: 「年バレネタですが『ウルトラ5つの誓い』を思い出しちゃって」
参考: ウルトラ5つの誓いとは (ウルトライツツノチカイとは) [単語記事] - ニコニコ大百科
RubyのValue Objectはこう使おう(RubyFlowより)
# 同リポジトリより
# Good
BigDecimal('100').to_i # => 数値を変えずに精度だけ下げる
# Bad
Quantity.new(10, 'm').to_i # => コンテキストが失われる: Quantity#amountとする方がずっといい
# Acceptable
Dates::Period.to_activercord # => コンテキストによってはあり
# Questionable
Dates::Period.to_regexp # => #regexpでいいんじゃね?
つっつきボイス: 「けっこうがっつり書いてあってよさそうです」「なぜGitHubリポジトリなのかはおいといて」「あのzverokさんだ↓」
Ruby: 「マジック」と呼ぶのをやめよう(翻訳)
QuickType.io: JSONを貼るとRubyやSwiftやJSのコードに変換するサイト(RubyFlowより)
![]()
同サイトより
Rubyの場合、例のdry-rbを使ってくれます。
![]()
同サイトより
![]()
同サイトより
つっつきボイス: 「お、これ便利かも」「Pythonが入ってないのが何となく男らしい」「逆変換もできたらいいな♡」
悪いのはRailsじゃない、Active Recordだっ(Hacklinesより)
# 同記事より
data = [
{ name: "Owner", email: "owner@example.com" },
{ name: "Employee", email: "employee@example.com" },
...
]
# Raw SQL
INSERT INTO users (name, email)
VALUES ("Owner", "owner@example.com"), ("Employee", "employee@example.com")
# Sequel
db[:users].multi_insert(data)
# ActiveRecord by #import
User.import(data.first.keys, data.map(&:values))
# Arel
table = Table.new(:users)
manager = Arel::InsertManager.new
manger.into(table)
manager.columns = [table[:name], table[:email]]
manager.values = manager.create_values_list(data.map(&values))
- 結局SQL構文知らないと使えない
- RubyによるSQL構文チェックがない
- オブジェクト指向じゃない
- メンテがつらい
- モデルにビジネスロジックだのエンティティ構造だの追加アクションだのしょぼいロジック定義が山盛りになる
つっつきボイス: 「PV狙いのタイトルっぽい」「悪いとしたらビュー周りかなと思った」「この人『Arelは悪くない、Sequelいいヤツ』って言ってますけど、Arelについてはちょっとどうかなー」「うーむ」「私は最終的には生SQLが最強だとこっそり信じてますけど」「生SQLは覇者」「ORMでやってても結局SQLチェックしますしね」「文中のRecursive Common Table Expressionって何だったかな(↓)」
参考: COMMON_TABLE_EXPRESSION (TRANSACT-SQL) | Microsoft Docs
私がRailsよりHanamiが好きな理由(Ruby Weeklyより)
![]()
hanamirb.orgより
- Repositoryパターンなところ
- アクションがクラスであるところ
- ビュークラスがあるところ
著者はあのRyan Biggさんです↓。
Railsの`CurrentAttributes`は有害である(翻訳)
SOLIDの原則その2: オープン/クローズの原則
# 同記事より
class UserCreateService
def initialize(params, validator: UserValidator)
@params = params
@validator = validator
end
def call
return false unless validator.new(params).validate
process_user_data
end
attr_reader :params, :validator
def process_user_data
...
end
end
RubyMineで速攻殺している自動チェック項目3つ(Hacklinesより)
とても短い記事です。
つっつきボイス: 「Cucumberとかスペルチェックはともかく、”Double quoted string”って式展開がない場合はシングルクォートにしろっていうアレですかね?」「RuboCopちゃんに怒られるから基本シングルクォートにする癖がついてる」「実はオフにする方法を知らないけどなっ: 玉突きで変更しないといけないし」
Rubyスタイルガイドを読む: 数値、文字列、日時(日付・時刻・時間)
海外のRuby/Railsカンファレンス
Ruby/Rails関連おすすめ情報源(RubyFlowより)
書籍やサイトやチュートリアルがずらっと並んでいます。
あるRails開発会社の会社概要(RubyFlowより)
開発ツールや進め方が割りと事細かに書かれています。全部字ばっかりなのが逆に珍しいかも。
ビューやヘルパーは別世界か
つっつきボイス: 「ちょうど最近この辺の話をよくしてたので」「そうそう、#lとか#tみたいにビュー全体で使うようなのをヘルパーに置くのはまだわかるんだけど、『これ汚いからビューから逃したい』みたいなのをグローバルなヘルパーに置くのはどうかな~っていつも思ってる」「さすがヘルパー嫌いマン」「Railsのヘルパーは、WordPressで言うfunctions.phpみたいなものって説明してもらって腑に落ちたことあります」
「a_matsudaさんといえばactive_decoratorの作者ですよね: モデル名と紐付いているデコレータのモジュールをビューに行くまでにこっそりインクルードするみたいな: まさにそういう話ですよね↑」「俺それ正解だと思うよマジで」
「ヘルパーに置いてグローバルになるくらいなら、いっそコントローラに書いちゃいますね: helper_methodっていうメソッド↓があって、これを使うとコントローラにヘルパーを書けちゃうんですよ」「へー!」「知らなかった」「しょっちゅうは使わないけど、ここぞというときに控えめに使う感じで: 内部の挙動はまだよく知らないし本当にいいものかどうかはちょっと微妙なんですが」
参考: Rails API helper_method
class ApplicationController < ActionController::Base
helper_method :current_user, :logged_in?
def current_user
@current_user ||= User.find_by(id: session[:user])
end
def logged_in?
current_user != nil
end
end
Railsの「雪だるまエンコーディング」問題が修正☃️
先ほど流れてきたので。
その他小粒記事
Ruby trunkより
特殊変数を排除してPathnameを高速化(継続)
Regexp#=~だと$&などの特殊変数を更新する分オーバーヘッドが生じるので、更新しないRegexp#match?に置き換えたとのことです。ベンチマークの書式がびしっと整ってます。
[Ruby] Kernelの特殊変数をできるだけ$記号なしで書いてみる
つっつきボイス: 「ちょっと話それるけど、名前がFileなのにパスっぽいものも渡されたりするとどうかと思うことがある」「それは確かによくないかも」
提案: キーがない場合にraiseする#dig!(継続)
hash = {
:name => {
:first => "Ariel",
:last => "Caplan"
}
}
hash.dig!(:name, :first) # => Ariel
hash.dig!(:name, :middle) # => nil ●これをraiseしたい
hash.dig!(:name, :first, :foo) # raises TypeError (String does not have #dig method)
「キーワード引数でできるのでは?」「deep_fetch gemでできる」という回答です。
つっつきボイス: 「ビックリマーク付きの#dig!か」「!はこの場合いいんだろうか?」
Ruby:「プリマドンナメソッド」の臭いの警告を私が受け入れるまで(翻訳)
提案: begin(またはdo)-else–endでrescueが抜けてたらsyntax errorにしたい(受理)
begin
p :foo
else
p :bar
end
# => :foo
# => :bar
joker10071002さんです。特にdoで始まるときにrescueを置き忘れやすいので、syntax errorにしたいとのことです。
つっつきボイス: 「自分的にはwarningのままの方がいいかなーという気がするけど」「そういえばエラー処理のelseとensureってどう違うんでしたっけ?」「elseは上のどれでもなかった場合で、eusureは結果にかかわらず必ず実行するやつだったかと」
なおその後acceptされました。
参考: Rubyリファレンスマニュアル begin
Ruby
RubyにもGolangのdeferが欲しいので作ってみた話
つっつきボイス: 「ちょうど上の話にも通じてる」「Goのdeferはブロックの外にも置けてRubyのensureより強力な印象ですね: まだ使ったことないけど」「JavaScriptのPromiseもDeferredって呼ばれてた」
参考: Golang の defer 文と panic/recover 機構について - CUBE SUGAR CONTAINER
参考: 非同期処理とPromise(Deferred)を背景から理解しよう - hifive
licensed: GitHub自ら提供する依存関係のライセンス照合/キャッシュgem(Ruby Weeklyより)
# 同リポジトリより
$ bundle exec licensed status
Checking licenses for 3 dependencies
Warnings:
.licenses/rubygem/bundler.txt:
- license needs reviewed: mit.
.licenses/rubygem/licensee.txt:
- cached license data missing
.licenses/bower/jquery.txt:
- license needs reviewed: mit.
- cached license data out of date
3 dependencies checked, 3 warnings found.
まだ1か月経ってない新しいgemです。類似のgemを取り上げたことがありました。
rakeタスクをきれいに書くコツ(Hacklinesより)
DHHのYouTubeチャンネルでヒントを得たそうです。
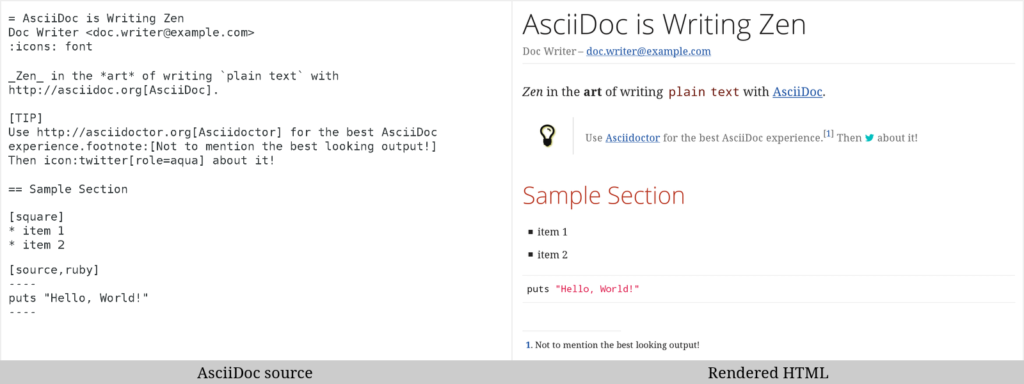
asciidoctor: AsciiDoc形式テキストプロセッサのRuby版(Awesome Rubyより)
![]()
= Hello, AsciiDoc!
Doc Writer <doc@example.com>
An introduction to http://asciidoc.org[AsciiDoc].
== First Section
* item 1
* item 2
[source,ruby]
puts "Hello, World!"
AsciiDocはこんな感じ↑で書けるようです。単なるMarkdownの置き換えではないと言ってます。
参考: What is AsciiDoc? Why do we need it? | Asciidoctor
参考: 脱Word、脱Markdown、asciidocでドキュメント作成する際のアレコレ
ヒアドキュメントで式展開#{}を展開させない方法(Hacklinesより)
# 同記事より
venue = "world"
str = <<-'EOF'
I'm the master of the #{venue} !
No you're dead bro..\n
EOF
2018年のRuby GUI開発事情(RubyFlowより)
![]()
saveriomiroddi.github.ioより
なお著者はGobyのcontributorであることを今思い出しました。
RubyのリゾルバでSSRFフィルタをバイパスされる脆弱性(Hacklinesより)
# 同記事より
irb(main):008:0> Resolv.getaddresses("127.0.0.1")
=> ["127.0.0.1"]
irb(main):009:0> Resolv.getaddresses("localhost")
=> ["127.0.0.1"]
irb(main):010:0> Resolv.getaddresses("127.000.000.1")
=> [] # 😱
参考: Rubyリファレンスマニュアル Resolv
SCSSコンパイラを自力で書いてみたお(RubyFlowより)
![]()
同記事より
RubyがTIOBEのトップ10言語に返り咲く(Hacklinesより)
![]()
tiobe.comより
つっつきボイス: 「記事のグラフ見ると、むしろC言語がいったん下がってからガッと上がっているのが気になる」「JavaとC以外はまだ混戦かなー」
Aaron Pattersonさんから
#kind_ofが悪手になる場合
どこかで「#is_a?は今は非推奨」とmatzがツイートしていた気がしましたが、そのエイリアスである#kind_of?もどうやらあまり使って欲しくない様子です。
つっつきボイス: 「Matzが#kind_of?警察やってる」「#is_a?が非推奨になったのは、確か名前がよくなかったからだったような」「『純粋なオブジェクト指向ならメッセージベースでやろうぜ』『クラスなんてものはオブジェクト間の通信には本来不要である』という趣旨なんでしょうね」
「質問者の方もそうだけど、Javaから来ると型チェックしたくなる気持ちはわかる」「Javaにはインターフェイスがあるから」「Rubyにはrespond_to?がある」
私もつい型チェック的思考に傾きかけてたかも。反省。
参考: RubyリファレンスマニュアルObject#respond_to?
「ところでRailsには?なしのrespondo_toというのがあってですね」「紛らわし!」「Railsを先にやると、Rubyのrespond_to?の方でむしろ首を傾げたりとか」「RSpecのrespond_toマッチャーも同じ過ぎるし」「名前がこれだけ似てて意味がまるで違うという」
参考: Rails API respond_to
Ruby生誕25周年記念: コミットのビジュアル表示
SQL
- Entity Attribute Values
- Multiple Values per Column
- UUID
つっつきボイス: 「EAVはSQLアンチパターンにも載っている定番中の定番っすね: 一度はやりたくなってしまうやつ」「略語になってるんですね」
「むかーしエンタープライズ系のJavaの本で『EAVはベストプラクティスのひとつである』みたいな記述があったんですが」「マジかーw」「いや、たぶんこれはメモリ構造に乗せてEAVする分にはよかったはず: RDBMSでやるもんじゃないですよもちろん」「後で検索が必要になったときに死ねるやつ」
「2.は今のRDBMSなら普通にできたりしますね: PostgreSQLのArrayとか」
PostgreSQLの全文検索でVACUUMを使うときにやるべきこと(Postgres Weeklyより)
つっつきボイス: 「出たーVACUUM ANALYZE: めちゃめちゃ重い」
PostgreSQLの新機能「シーケンス」のメリットと落とし穴(Postgres Weeklyより)
オーストラリアでこの3月に行われたRubyカンファレンスであるRubyConf Auでの発表です。
JavaScript
prettier: JS界のRuboCop
![]()
同リポジトリよりより
★めちゃ多いです。
JavaScriptのエレガントな「ROROパターン」(Frontend Weeklyより)
割りと長い記事です。ROROは「Receive an object, return an object」だそうです。RubyのPOROとは違いました。
Virtual DOMを使わないことで速くしたそうです。
Glimmer.jsとPreact.jsのパフォーマンス比較(JSer.infoより)
Linkedinの技術ブログです。
CSS/HTML/フロントエンド
Tumult Hype: フロントのアニメーション表示を徹底制御(Hacklinesより)
<a https://tumult.com/hype/”>![]()
同記事より
HoudiniプロジェクトのCSS Paint API(Frontend Focusより)
Chrome 65以降でないと動かないので、brew cuで速攻Chromeをアップグレードしました。以下で「Fail」が出るブラウザではできないそうです。
See the Pen CSS Paint API Detection by Will Boyd (@lonekorean) on CodePen.
動画: Chromeの新機能「Local Overrides」でパフォーマンス上の仮説をテストする(Frontend Focusより)
「King’s Pawn Game」に学ぶUIデザイン(Frontend Weeklyより)
![]()
同記事より
UIデザイナー向けの記事です。King’s Pawn Gameは、チェスの序盤の定石のようです。
参考: Wikipedia-en King’s Pawn Game
See the Pen Notched Boxes by Chris Coyier (@chriscoyier) on CodePen.
その他
Stackoverflowのアンケート結果
かなり長いです。
MacのiTerm2で出力を任意のエディタに送り込む(Hacklinesより)
AppleScriptの小ネタです。
若手開発者サバイバルガイド: コードが動かないときにうまく先輩に伝えるには(Hacklinesより)
つっつきボイス: 「これも翻訳打診してみますね」
HomebrewとPythonバージョンの混乱
Mathpix snipping tool: 数式を撮影するとLaTeXに変換するスマホアプリ
よく見たら昨年からiPhoneにインストールしてました。どっちかというとソルバーです。
番外
「いいこと聞いた」と思うかどうかが分かれ目?
ソイレントといえば
私の年だとソイレント・グリーンですが、ゼノギアスの方が有名っぽいですね。
たけのこ
巨星墜つ
モンティ・パイソンに出演したホーキング博士も素敵でした。
今週は以上です。
バックナンバー(2018年度)
週刊Railsウォッチ(20180309)RubyGems.orgのTLS 1.0/1.1接続非推奨、2年に1度のRailsアンケート、DockerのMoby Project、Ruby拡張をRustで書けるruruほか
今週の主なニュースソース
ソースの表記されていない項目は独自ルート(TwitterやRSSなど)です。
![]()
![]()
![]()
![]()
![160928_1638_XvIP4h]()
![Hacklines]()
![postgres_weekly_banner]()
![frontendweekly_banner_captured]()
![frontendfocus_banner_captured]()
![javascriptweekly_logo_captured]()
![jser.info_logo_captured]()





















 railsdiff.org
railsdiff.org 





 (@Savannahdworth)
(@Savannahdworth) 

























































 。
。
 。
。